Dataset
In this study, we first propose VideoXum, an enriched large-scale dataset for cross-modal video summarization. The dataset is built on ActivityNet Captions, a large-scale public video captioning benchmark. We hire workers to annotate ten shortened video summaries for each long source video according to the corresponding captions. VideoXum contains 14K long videos with 140K pairs of aligned video and text summaries.
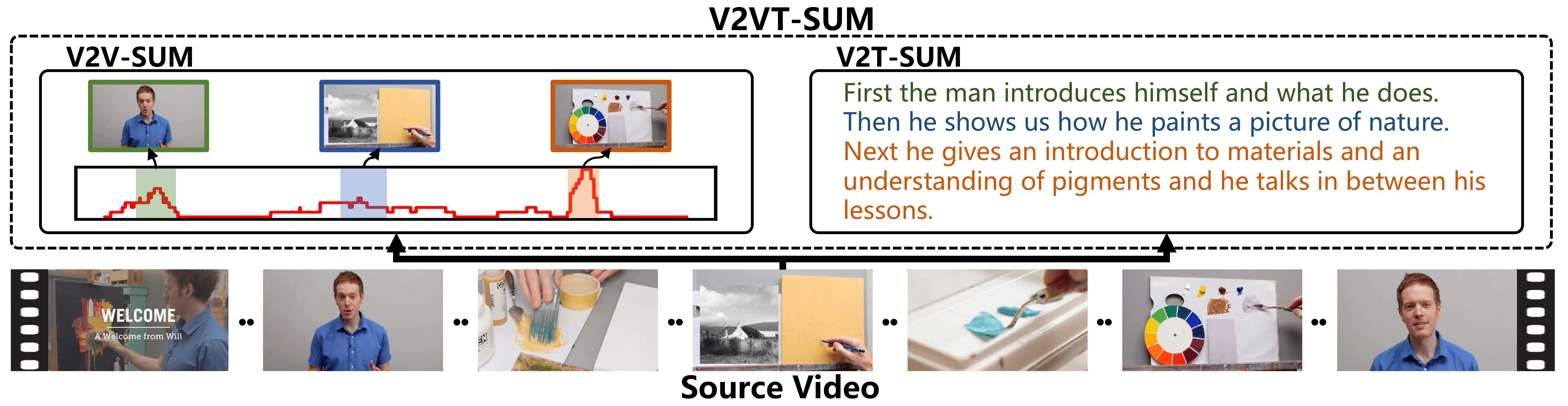
Illustration of our V2X-SUM task. A long source video (bottom) can be summarized into a shortened videoand a text narrative (top). The video and text summaries should be semantically aligned.
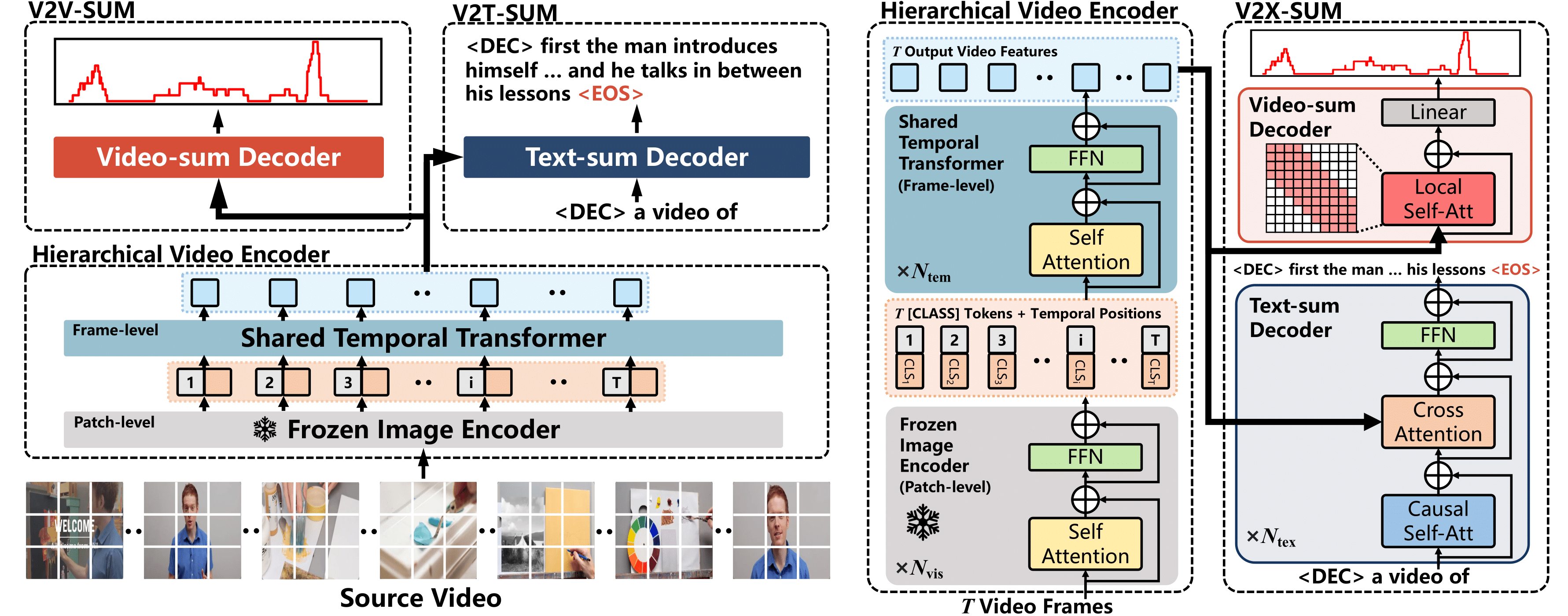
Our goal is to extend the traditional single-modal video summarization task to a cross-modal video summarization task, referred to as V2X-SUM to meet the demands of broader application scenarios (e.g., movie trailer generation and narrative generation). According to the target modality of the generated summaries, we categorize our proposed V2X-SUM task into three subtasks:
- Video-to-Video Summarization (V2V-SUM). This task requires models to identify the most important segments from the source video and generate an abridged version of the source video.
- Video-to-Text Summarization (V2T-SUM). In this task, models need to summarize the main content of the source video and generate a short text description.
- Video-to-Video&Text Summarization (V2VT-SUM). This task requires models to summarize a short video and the corresponding narrative from a source video simultaneously. Moreover, the semantics of these two modalities of summaries should be well aligned.